



AI and Efficiency
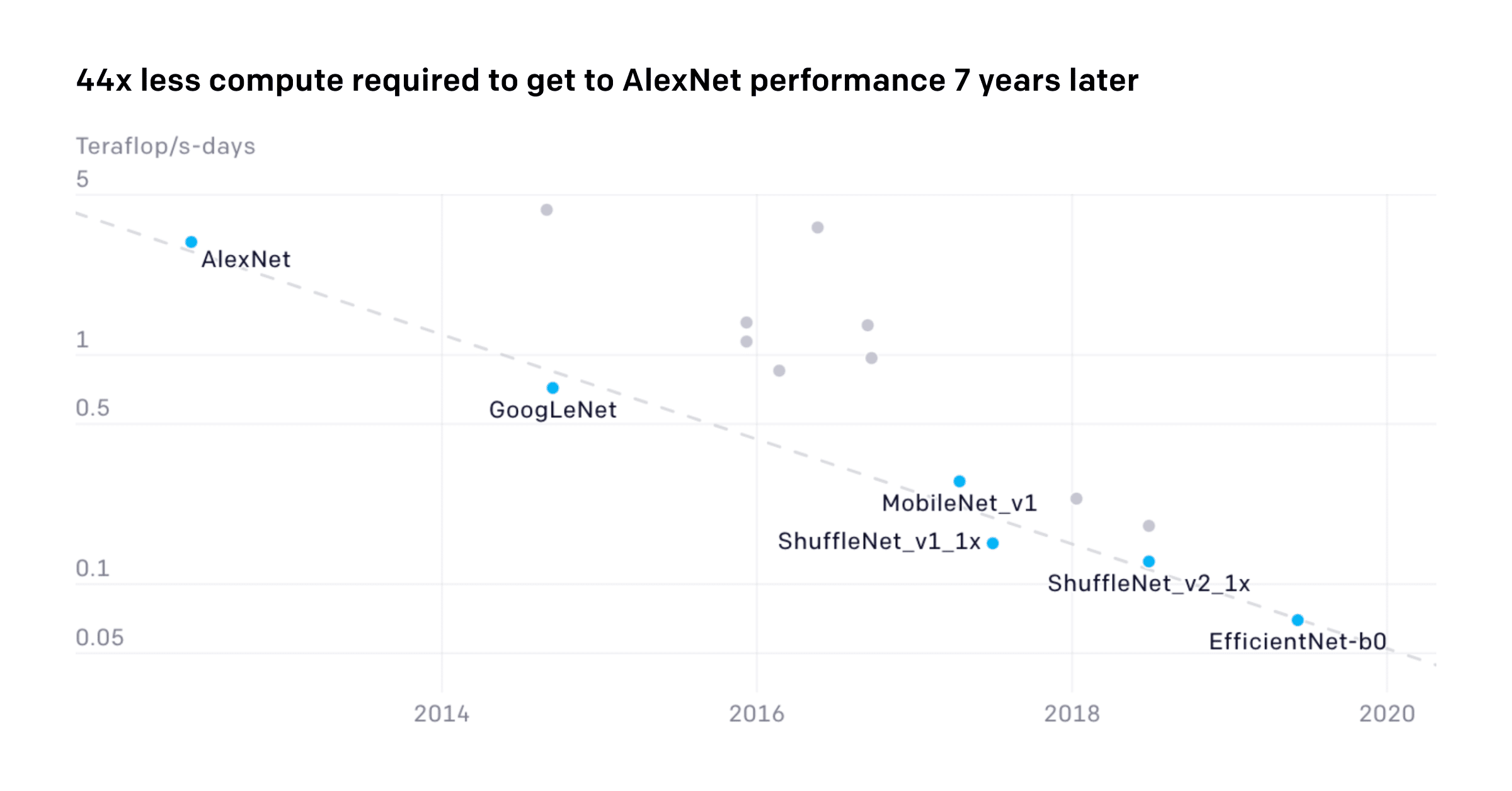
We’re releasing an analysis showing that since 2012 the amount of compute needed to train a neural net to the same performance on ImageNet classification has been decreasing by a factor of 2 every 16 months. Compared to 2012, it now takes 44 times less compute to train a neural network to the level of AlexNet (by contrast, Moore’s Law would yield an 11x cost improvement over this period). Our results suggest that for AI tasks with high levels of recent investment, algorithmic progress has yielded more gains than classical hardware efficiency.
Algorithmic improvement is a key factor driving the advance of AI. It’s important to search for measures that shed light on overall algorithmic progress, even though it’s harder than measuring such trends in compute.
44x less compute required to get to AlexNet performance 7 years later
Measuring efficiency
Algorithmic efficiency can be defined as reducing the compute needed to train a specific capability. Efficiency is the primary way we measure algorithmic progress on classic computer science problems like sorting. Efficiency gains on traditional problems like sorting are more straightforward to measure than in ML because they have a clearer measure of task difficulty.[1] However, we can apply the efficiency lens to machine learning by holding performance constant. Efficiency trends can be compared across domains like DNA sequencing (10-month doubling), solar energy (6-year doubling), and transistor density (2-year doubling).
For our analysis, we primarily leveraged open-source re-implementations to measure progress on AlexNet level performance over a long horizon. We saw a similar rate of training efficiency improvement for ResNet-50 level performance on ImageNet (17-month doubling time). We saw faster rates of improvement over shorter timescales in Translation, Go, and Dota 2:
- Within translation, the Transformer surpassed seq2seq performance on English to French translation on WMT’14 with 61x less training compute 3 years later.
- We estimate AlphaZero took 8x less compute to get to AlphaGoZero level performance 1 year later.
- OpenAI Five Rerun required 5x less training compute to surpass OpenAI Five (which beat the world champions, OG) 3 months later.
It can be helpful to think of compute in 2012 not being equal to compute in 2019 in a similar way that dollars need to be inflation-adjusted over time. A fixed amount of compute could accomplish more in 2019 than in 2012. One way to think about this is that some types of AI research progress in two stages, similar to the “tick tock” model of development seen in semiconductors; new capabilities (the “tick”) typically require a significant amount of compute expenditure to obtain, then refined versions of those capabilities (the “tock”) become much more efficient to deploy due to process improvements.
Increases in algorithmic efficiency allow researchers to do more experiments of interest in a given amount of time and money. In addition to being a measure of overall progress, algorithmic efficiency gains speed up future AI research in a way that’s somewhat analogous to having more compute.
Other measures of AI progress
In addition to efficiency, many other measures shed light on overall algorithmic progress in AI. Training cost in dollars is related, but less narrowly focused on algorithmic progress because it’s also affected by improvement in the underlying hardware, hardware utilization, and cloud infrastructure. Sample efficiency is key when we’re in a low data regime, which is the case for many tasks of interest. The ability to train models faster also speeds up research and can be thought of as a measure of the parallelizability of learning capabilities of interest. We also find increases in inference efficiency in terms of GPU time, parameters, and flops meaningful, but mostly as a result of their economic implications[2] rather than their effect on future research progress. Shufflenet achieved AlexNet-level performance with an 18x inference efficiency increase in 5 years (15-month doubling time), which suggests that training efficiency and inference efficiency might improve at similar rates. The creation of datasets/environments/benchmarks is a powerful method of making specific AI capabilities of interest more measurable.
Primary limitations
- We have only a small number of algorithmic efficiency data points on a few tasks. It’s unclear the degree to which the efficiency trends we’ve observed generalize to other AI tasks. Systematic measurement could make it clear whether an algorithmic equivalent to Moore’s Law[3] in the domain of AI exists, and if it exists, clarify its nature. We consider this a highly interesting open question. We suspect we’re more likely to observe similar rates of efficiency progress on similar tasks. By similar tasks, we mean tasks within these sub-domains of AI, on which the field agrees we’ve seen substantial progress, and that have comparable levels of investment (compute and/or researcher time).
- Even though we believe AlexNet represented a lot of progress, this analysis doesn’t attempt to quantify that progress. More generally, the first time a capability is created, algorithmic breakthroughs may have reduced the resources required from totally infeasible[4] to merely high. We think new capabilities generally represent a larger share of overall conceptual progress than observed efficiency increases of the type shown here.
- This analysis focuses on the final training run cost for an optimized model rather than total development costs. Some algorithmic improvements make it easier to train a model by making the space of hyperparameters that will train stably and get good final performance much larger. On the other hand, architecture searches increase the gap between the final training run cost and total training costs.
- We don’t speculate[5] on the degree to which we expect efficiency trends will extrapolate in time, we merely present our results and discuss the implications if the trends persist.
Measurement and AI policy
We believe that policymaking related to AI will be improved by a greater focus on the measurement and assessment of AI systems, both in terms of technical attributes and societal impact. We think such measurement initiatives can shed light on important questions in policy; our AI and Compute analysis suggests policymakers should increase funding for compute resources for academia, so that academic research can replicate, reproduce, and extend industry research. This efficiency analysis suggests that policymakers could develop accurate intuitions about the cost of deploying AI capabilities—and how these costs are going to alter over time—by more closely assessing the rate of improvements in efficiency for AI systems.
Tracking efficiency going forward
If large scale compute continues to be important to achieving state of the art (SOTA) overall performance in domains like language and games then it’s important to put effort into measuring notable progress achieved with smaller amounts of compute (contributions often made by academic institutions). Models that achieve training efficiency state of the arts on meaningful capabilities are promising candidates for scaling up and potentially achieving overall top performance. Additionally, figuring out the algorithmic efficiency improvements are straightforward[6] since they are just a particularly meaningful slice of the learning curves that all experiments generate.
We also think that measuring long run trends in efficiency SOTAs will help paint a quantitative picture of overall algorithmic progress. We observe that hardware and algorithmic efficiency gains are multiplicative and can be on a similar scale over meaningful horizons, which suggests that a good model of AI progress should integrate measures from both.
Our results suggest that for AI tasks with high levels of investment (researcher time and/or compute) algorithmic efficiency might outpace gains from hardware efficiency (Moore’s Law). Moore’s Law was coined in 1965 when integrated circuits had a mere 64 transistors (6 doublings) and naively extrapolating it out predicted personal computers and smartphones (an iPhone 11 has 8.5 billion transistors). If we observe decades of exponential improvement in the algorithmic efficiency of AI, what might it lead to? We’re not sure. That these results make us ask this question is a modest update for us towards a future with powerful AI services and technology.
For all these reasons, we’re going to start tracking efficiency SOTAs publicly. We’ll start with vision and translation efficiency benchmarks (ImageNet[7] and WMT14), and we’ll consider adding more benchmarks over time. We believe there are efficiency SOTAs on these benchmarks we’re unaware of and encourage the research community to submit them here (we’ll give credit to original authors and collaborators).
Industry leaders, policymakers, economists, and potential researchers are all trying to better understand AI progress and decide how much attention they should invest and where to direct it. Measurement efforts can help ground such decisions. If you’re interested in this type of work, consider applying to work at OpenAI’s Foresight or Policy team!
Go to Source
Author: Danny Hernandez
https://openai.com/blog/ai-and-efficiency/
