



Introducing Text and Code Embeddings in the OpenAI API
We are introducing embeddings, a new endpoint in the OpenAI API that makes it easy to perform natural language and code tasks like semantic search, clustering, topic modeling, and classification. Embeddings are numerical representations of concepts converted to number sequences, which make it easy for computers to understand the relationships between those concepts. Our embeddings outperform top models in 3 standard benchmarks, including a 20% relative improvement in code search.
Embeddings are useful for working with natural language and code, because they can be readily consumed and compared by other machine learning models and algorithms like clustering or search.






Embeddings that are numerically similar are also semantically similar. For example, the embedding vector of “canine companions say” will be more similar to the embedding vector of “woof” than that of “meow.”


The new endpoint uses neural network models, which are descendants of GPT-3, to map text and code to a vector representation—“embedding” them in a high-dimensional space. Each dimension captures some aspect of the input.
The new /embeddings endpoint in the OpenAI API provides text and code embeddings with a few lines of code:
import openai
response = openai.Embedding.create(
input="canine companions say",
engine="text-similarity-davinci-001")
We’re releasing three families of embedding models, each tuned to perform well on different functionalities: text similarity, text search, and code search. The models take either text or code as input and return an embedding vector.
| Models | Use Cases | |
|---|---|---|
| Text similarity: Captures semantic similarity between pieces of text. | text-similarity-{ada, babbage, curie, davinci}-001 | Clustering, regression, anomaly detection, visualization |
| Text search: Semantic information retrieval over documents. | text-search-{ada, babbage, curie, davinci}-{query, doc}-001 | Search, context relevance, information retrieval |
| Code search: Find relevant code with a query in natural language. | code-search-{ada, babbage}-{code, text}-001 | Code search and relevance |
Text Similarity Models
Text similarity models provide embeddings that capture the semantic similarity of pieces of text. These models are useful for many tasks including clustering, data visualization, and classification.
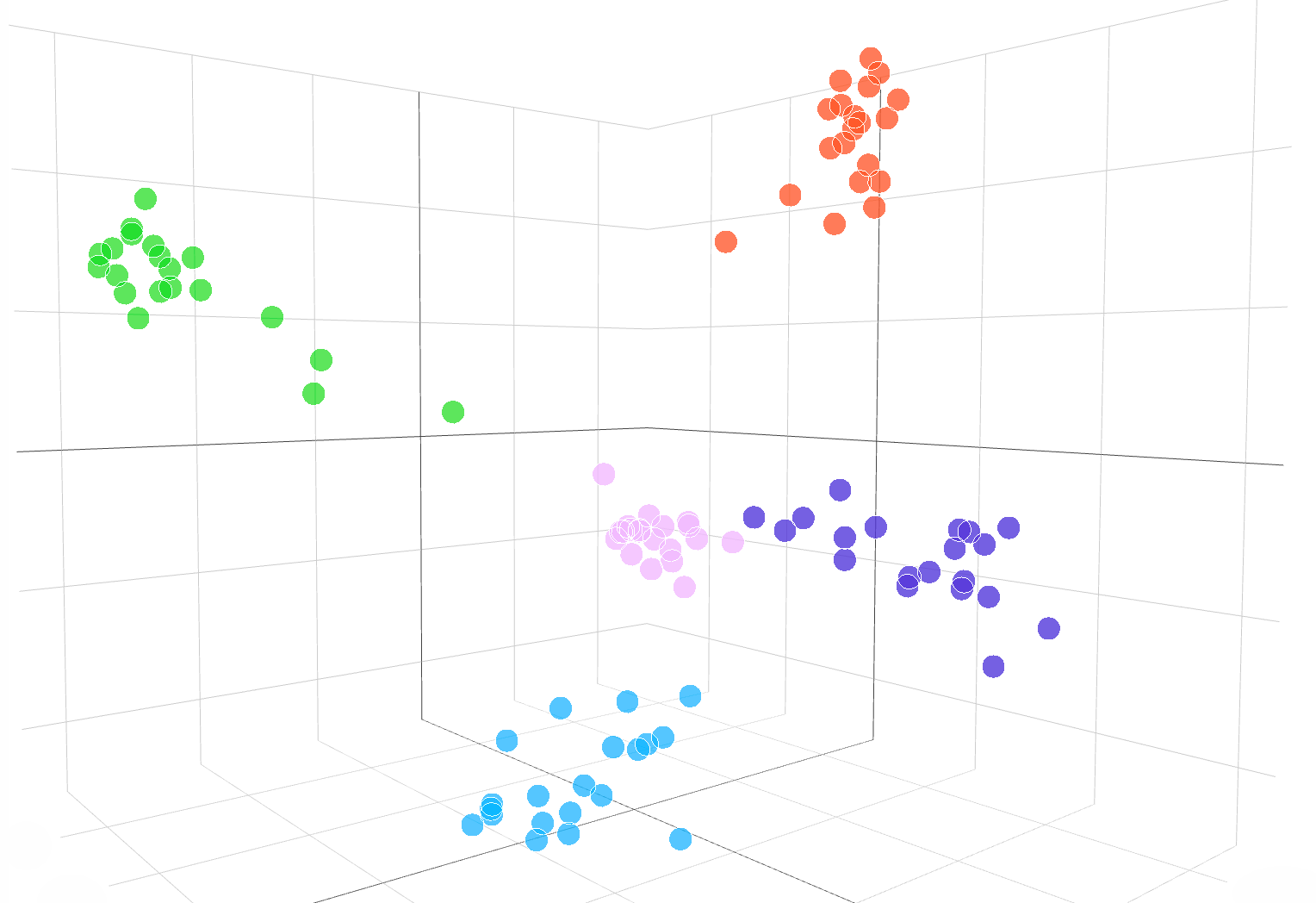
The following interactive visualization shows embeddings of text samples from the DBpedia dataset:
Embeddings from the text-similarity-babbage-001 model, applied to the DBpedia dataset. We randomly selected 100 samples from the dataset covering 5 categories, and computed the embeddings via the /embeddings endpoint. The different categories show up as 5 clear clusters in the embedding space. To visualize the embedding space, we reduced the embedding dimensionality from 2048 to 3 using PCA. The code for how to visualize embedding space in 3D dimension is available here.
To compare the similarity of two pieces of text, you simply use the dot product on the text embeddings. The result is a “similarity score”, sometimes called “cosine similarity,” between –1 and 1, where a higher number means more similarity. In most applications, the embeddings can be pre-computed, and then the dot product comparison is extremely fast to carry out.
import openai, numpy as np
resp = openai.Embedding.create(
input=["feline friends go", "meow"],
engine="text-similarity-davinci-001")
embedding_a = resp['data'][0]['embedding']
embedding_b = resp['data'][1]['embedding']
similarity_score = np.dot(embedding_a, embedding_b)
One popular use of embeddings is to use them as features in machine learning tasks, such as classification. In machine learning literature, when using a linear classifier, this classification task is called a “linear probe.” Our text similarity models achieve new state-of-the-art results on linear probe classification in SentEval (Conneau et al., 2018), a commonly used benchmark for evaluating embedding quality.
Linear probe classification over 7 datasets
Text Search Models
Text search models provide embeddings that enable large-scale search tasks, like finding a relevant document among a collection of documents given a text query. Embedding for the documents and query are produced separately, and then cosine similarity is used to compare the similarity between the query and each document.
Embedding-based search can generalize better than word overlap techniques used in classical keyword search, because it captures the semantic meaning of text and is less sensitive to exact phrases or words. We evaluate the text search model’s performance on the BEIR (Thakur, et al. 2021) search evaluation suite and obtain better search performance than previous methods. Our text search guide provides more details on using embeddings for search tasks.
Average accuracy over 11 search tasks in BEIR
Code Search Models
Code search models provide code and text embeddings for code search tasks. Given a collection of code blocks, the task is to find the relevant code block for a natural language query. We evaluate the code search models on the CodeSearchNet (Husian et al., 2019) evaluation suite where our embeddings achieve significantly better results than prior methods. Check out the code search guide to use embeddings for code search.
Average accuracy over 6 programming languages
Examples of the Embeddings API in Action
JetBrains Research
JetBrains Research’s Astroparticle Physics Lab analyzes data like The Astronomer’s Telegram and NASA’s GCN Circulars, which are reports that contain astronomical events that can’t be parsed by traditional algorithms.
Powered by OpenAI’s embeddings of these astronomical reports, researchers are now able to search for events like “crab pulsar bursts” across multiple databases and publications. Embeddings also achieved 99.85% accuracy on data source classification through k-means clustering.
FineTune Learning
FineTune Learning is a company building hybrid human-AI solutions for learning, like adaptive learning loops that help students reach academic standards.
OpenAI’s embeddings significantly improved the task of finding textbook content based on learning objectives. Achieving a top-5 accuracy of 89.1%, OpenAI’s text-search-curie embeddings model outperformed previous approaches like Sentence-BERT (64.5%). While human experts are still better, the FineTune team is now able to label entire textbooks in a matter of seconds, in contrast to the hours that it took the experts.
Comparison of our embeddings with Sentence-BERT, GPT-3 search and human subject-matter experts for matching textbook content with learned objectives. We report accuracy@k, the number of times the correct answer is within the top-k predictions.
Fabius
Fabius helps companies turn customer conversations into structured insights that inform planning and prioritization. OpenAI’s embeddings allow companies to more easily find and tag customer call transcripts with feature requests.
For instance, customers might use words like “automated” or “easy to use” to ask for a better self-service platform. Previously, Fabius was using fuzzy keyword search to attempt to tag those transcripts with the self-service platform label. With OpenAI’s embeddings, they’re now able to find 2x more examples in general, and 6x–10x more examples for features with abstract use cases that don’t have a clear keyword customers might use.
All API customers can get started with the embeddings documentation for using embeddings in their applications.
Go to Source
Author: Arvind Neelakantan
https://openai.com/blog/introducing-text-and-code-embeddings/
